LR: Inference + conditions
Nov 13, 2023
Statistician of the day - Alejandra Castillo
Alejandra Castillo did her undergraduate work at Pomona College in Mathematics and her MS (2019) and PhD (2023) at Oregon State University in Statistics.
Dr. Castillo’s research lies at the intersection of unsupervised learning, dimension reduction, and inference, with applications in clinical trial design. Some of her work explores how to use baseline demographic information collected before randomization to a clinical trial, particularly as the baseline information changes during the course of the trial.

MS Thesis: Castillo A. On the Use of Baseline Values in Randomized Clinical Trials, MS Thesis, Oregon State, 2019.
Empirical logit plot in R (quantitative predictor)
Created using dplyr and ggplot functions.
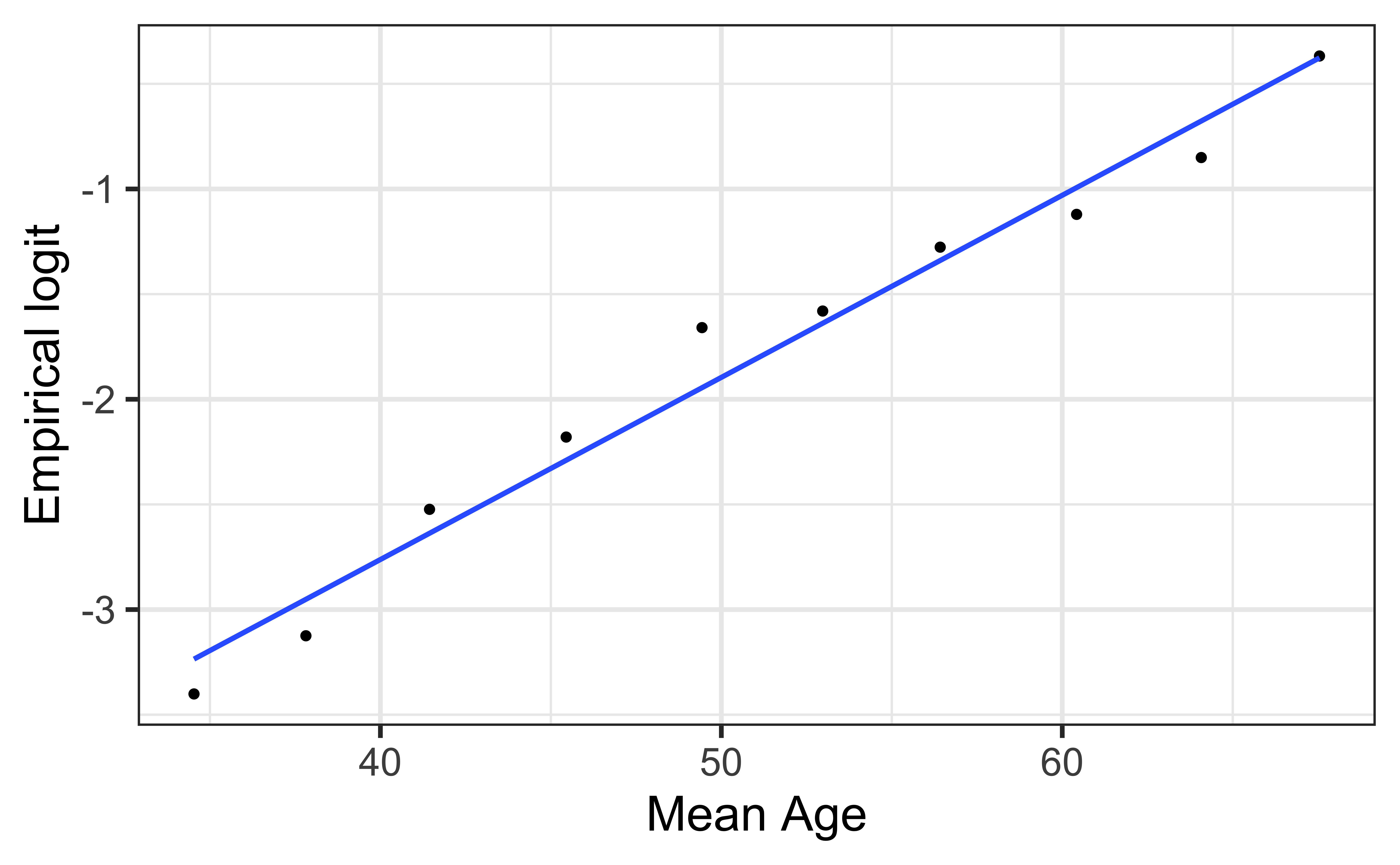
Empirical logit plot in R (quantitative predictor)
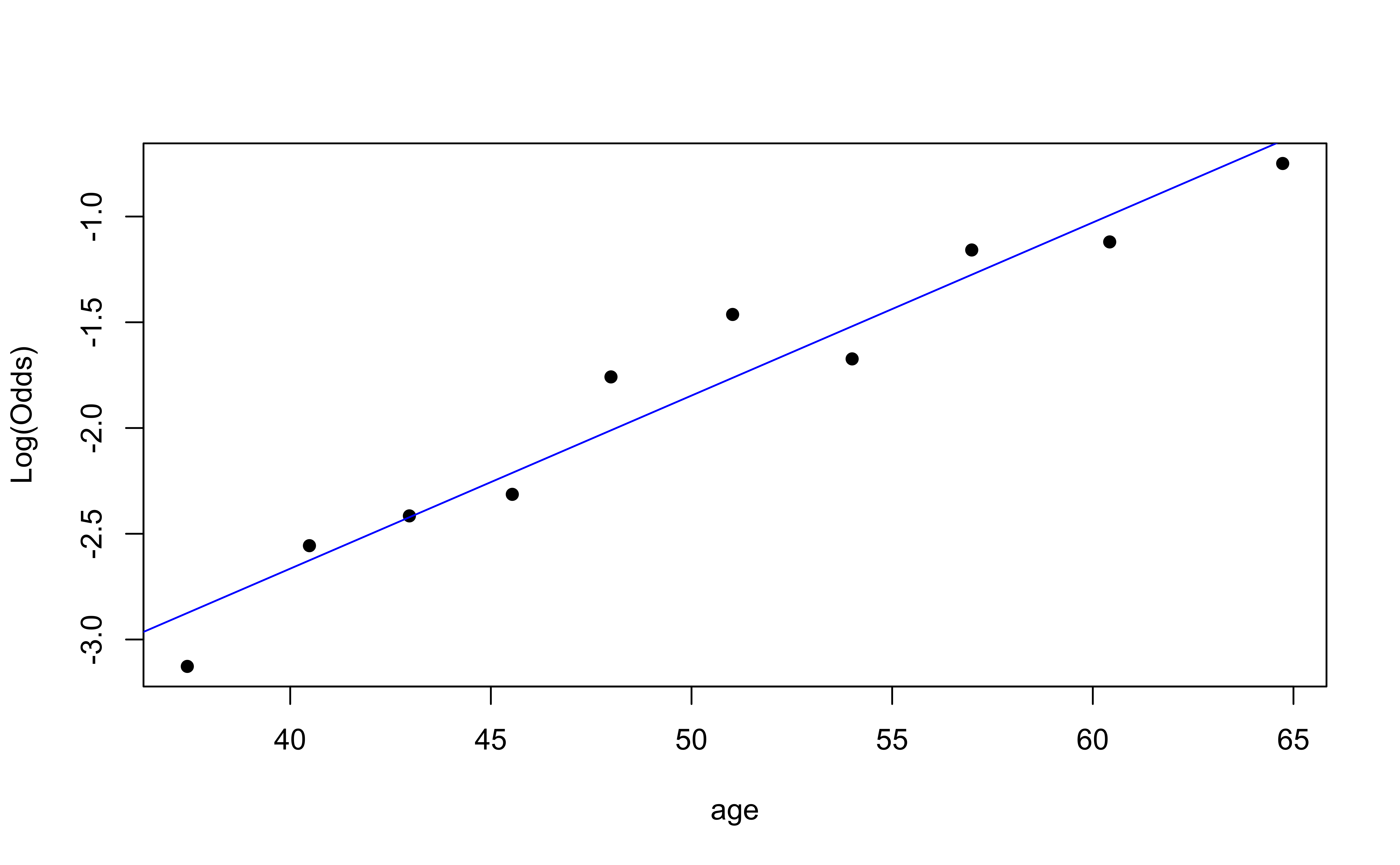
Using the emplogitplot1 function from the Stat2Data R package
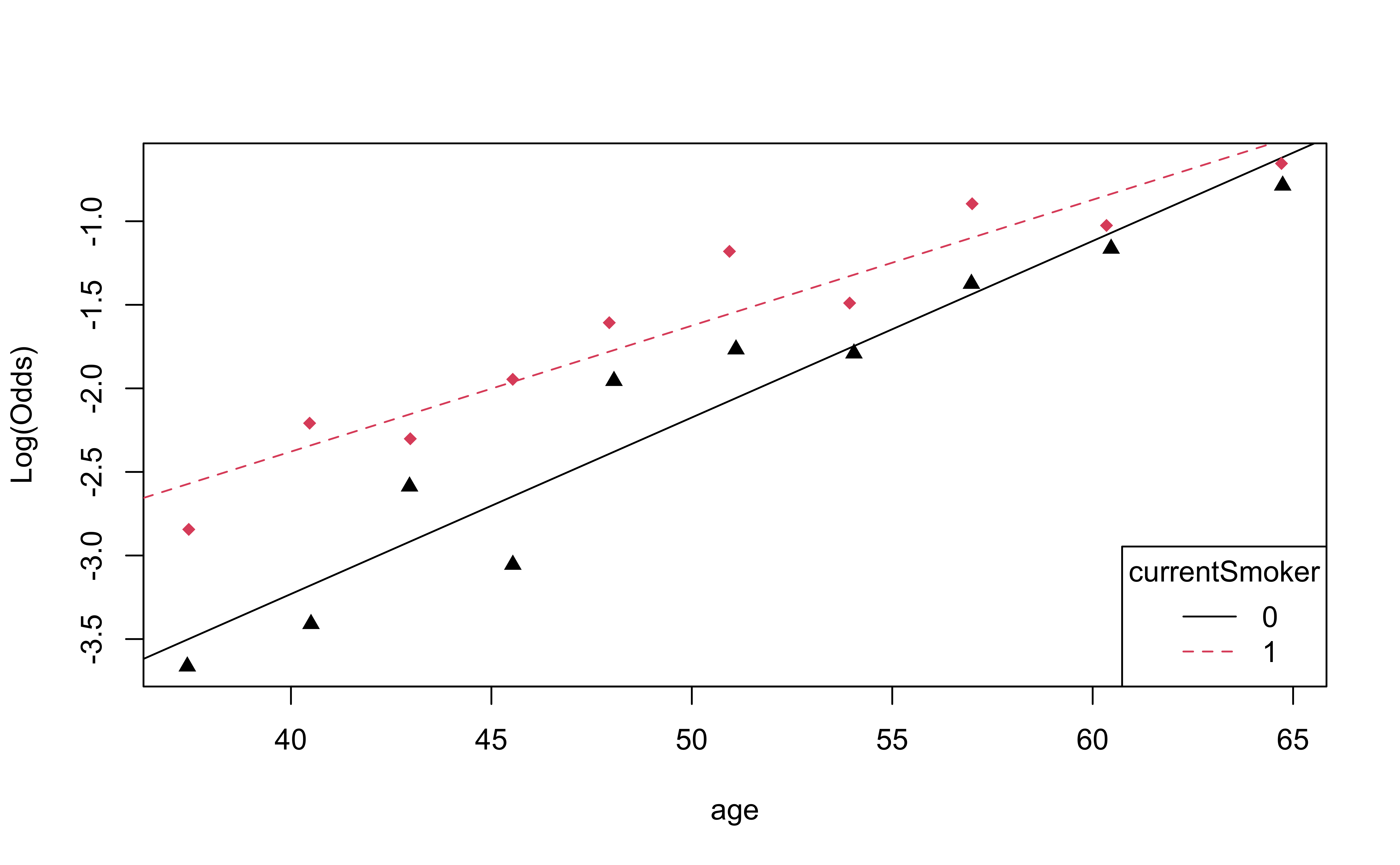
Empirical logit plot in R (interactions)
Using the emplogitplot2 function from the Stat2Data R package
Checking linearity
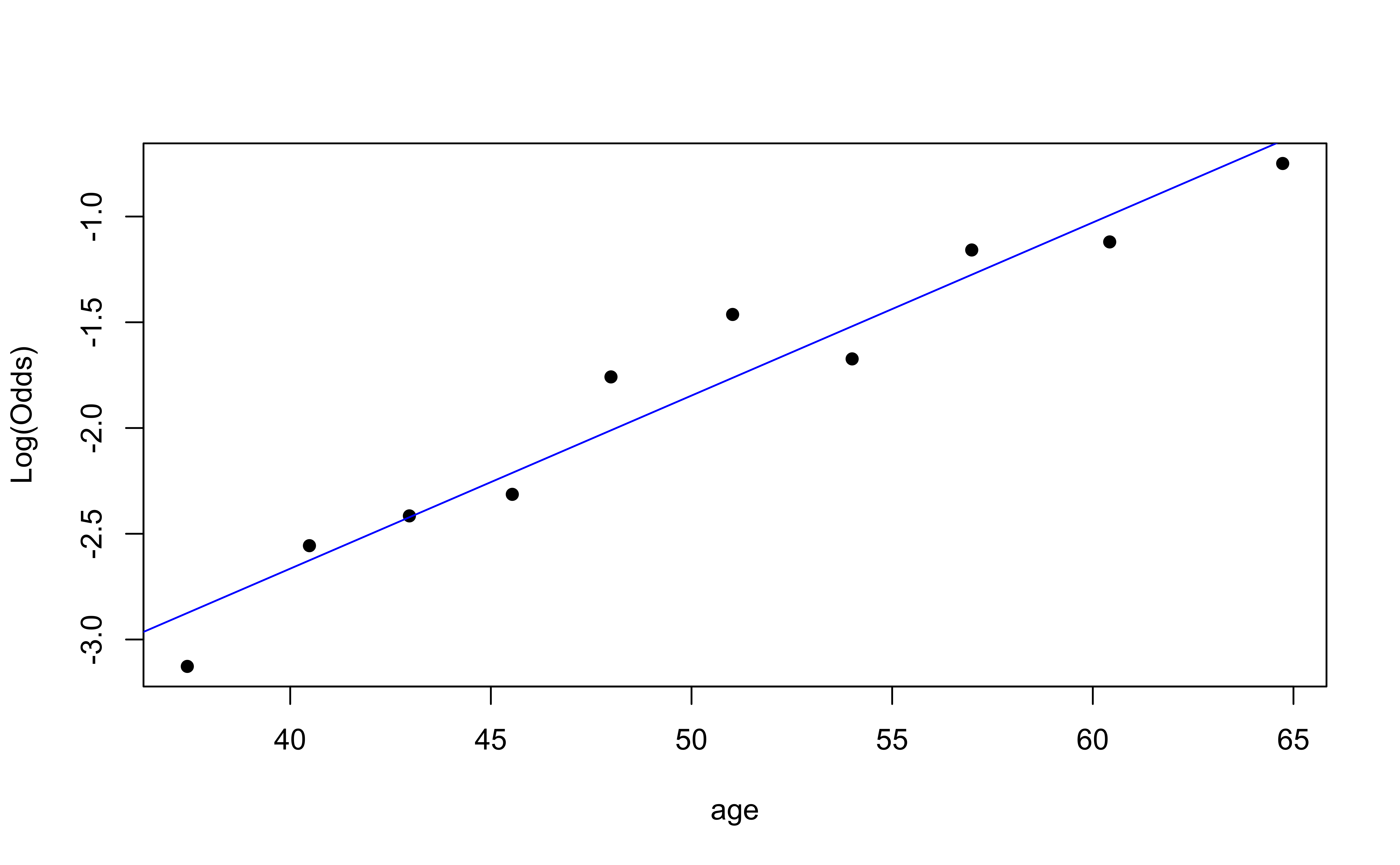
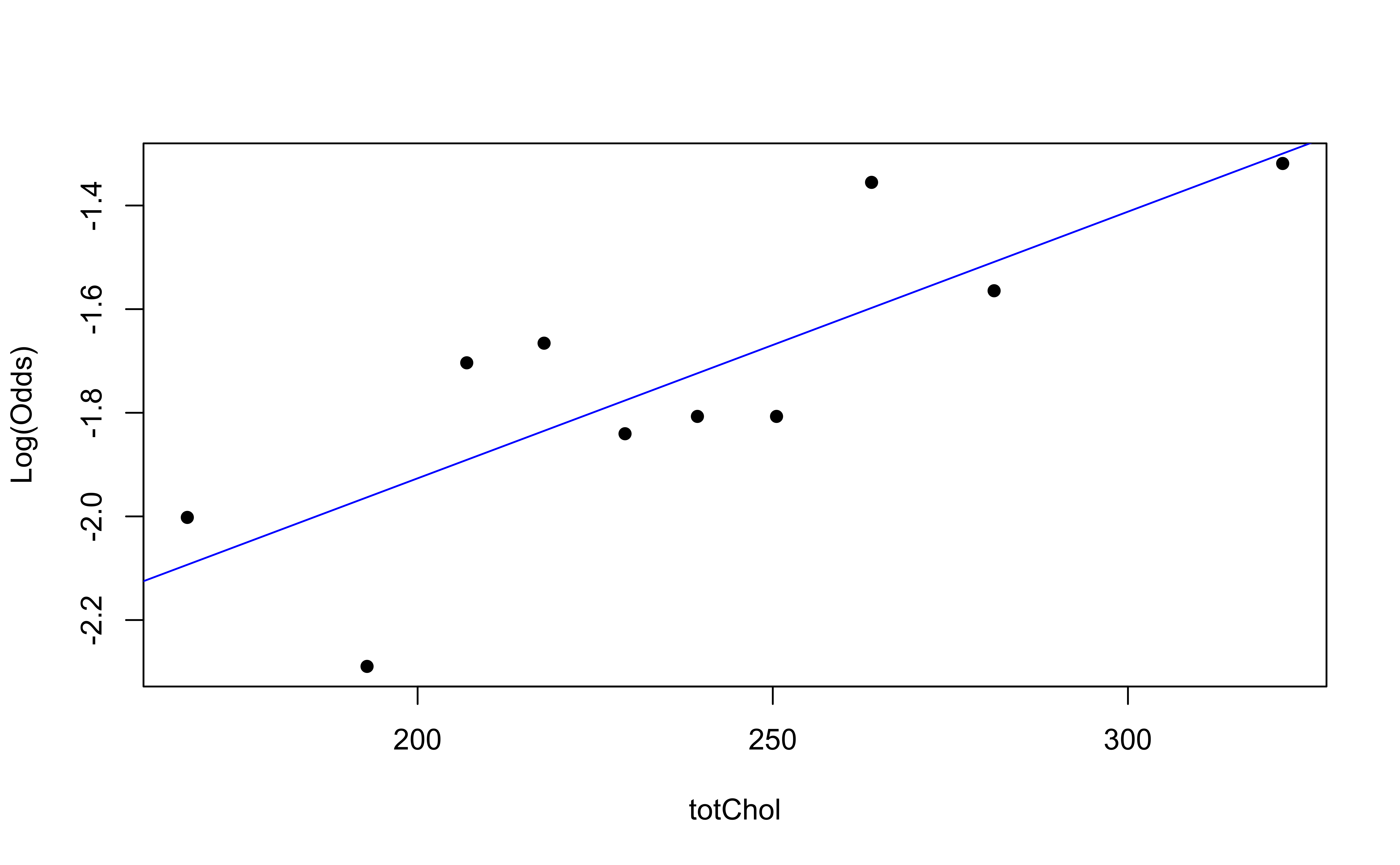
✅ The linearity condition is satisfied. There is a linear relationship between the empirical logit and the predictor variables.
Checking independence
- We can check the independence condition based on the context of the data and how the observations were collected.
- Independence is most often violated if the data were collected over time or there is a strong spatial relationship between the observations.
✅ The independence condition is satisfied. It is reasonable to conclude that the participants’ health characteristics are independent of one another.
![]()