# load packages
library(tidyverse) # for data wrangling
library(tidymodels) # for modeling
library(fivethirtyeight) # for the fandango dataset
library(knitr) # for formatting tables
# set default theme and larger font size for ggplot2
ggplot2::theme_set(ggplot2::theme_bw(base_size = 16))
# set default figure parameters for knitr
knitr::opts_chunk$set(
fig.width = 8,
fig.asp = 0.618,
fig.retina = 3,
dpi = 300,
out.width = "80%"
)Simple Linear Regression
Sep 06, 2023
Movie scores
- Data behind the FiveThirtyEight story Be Suspicious Of Online Movie Ratings, Especially Fandango’s
- In the fivethirtyeight package:
fandango - Contains every film released in 2014 and 2015 that has at least 30 fan reviews on Fandango, an IMDb score, Rotten Tomatoes critic and user ratings, and Metacritic critic and user scores




Movie scores data
The data set contains the “Tomatometer” score (critics) and audience score (audience) for 146 movies rated on rottentomatoes.com.
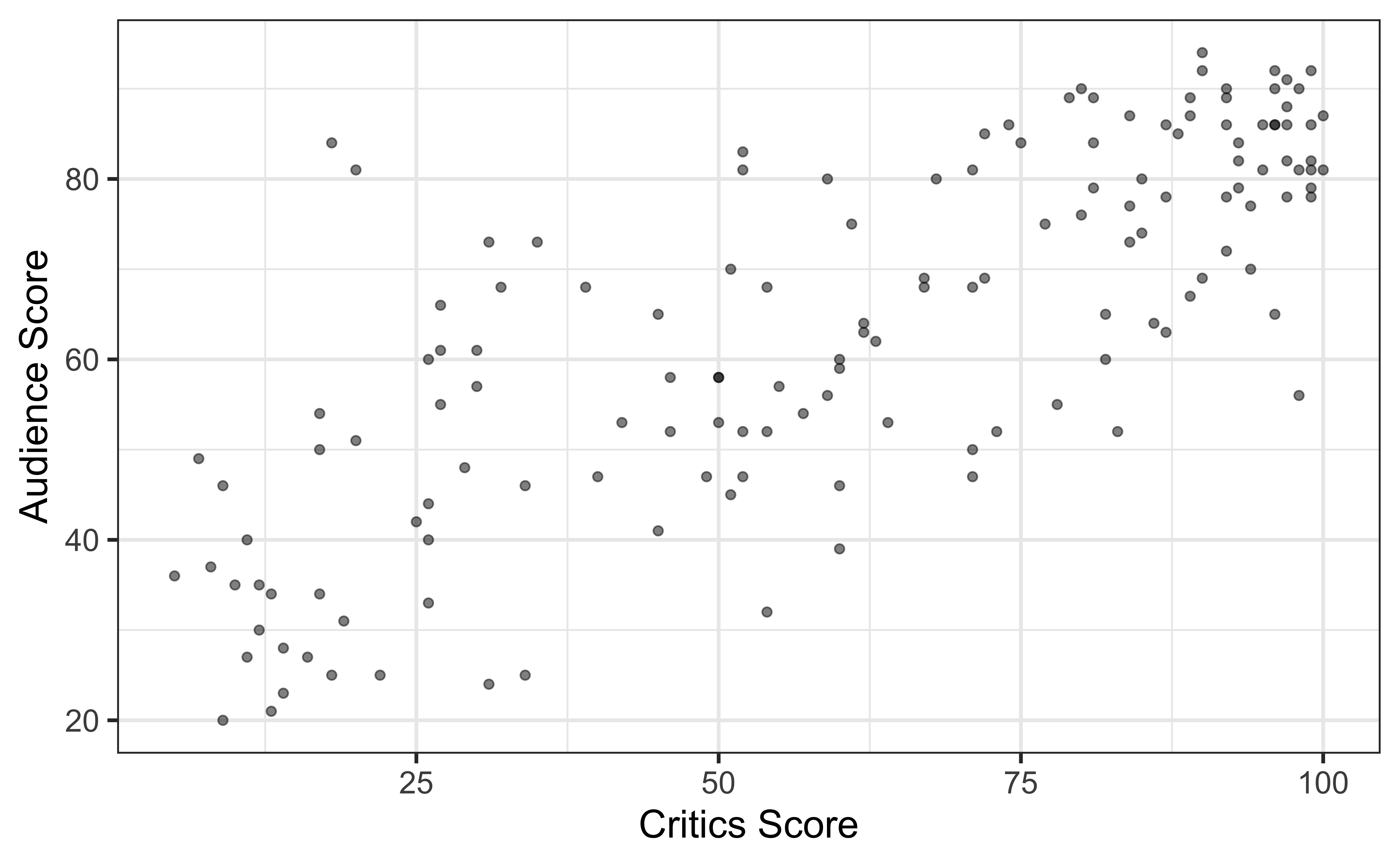
Movie ratings data
Goal: Fit a line to describe the relationship between the critics score and audience score.
`geom_smooth()` using formula = 'y ~ x'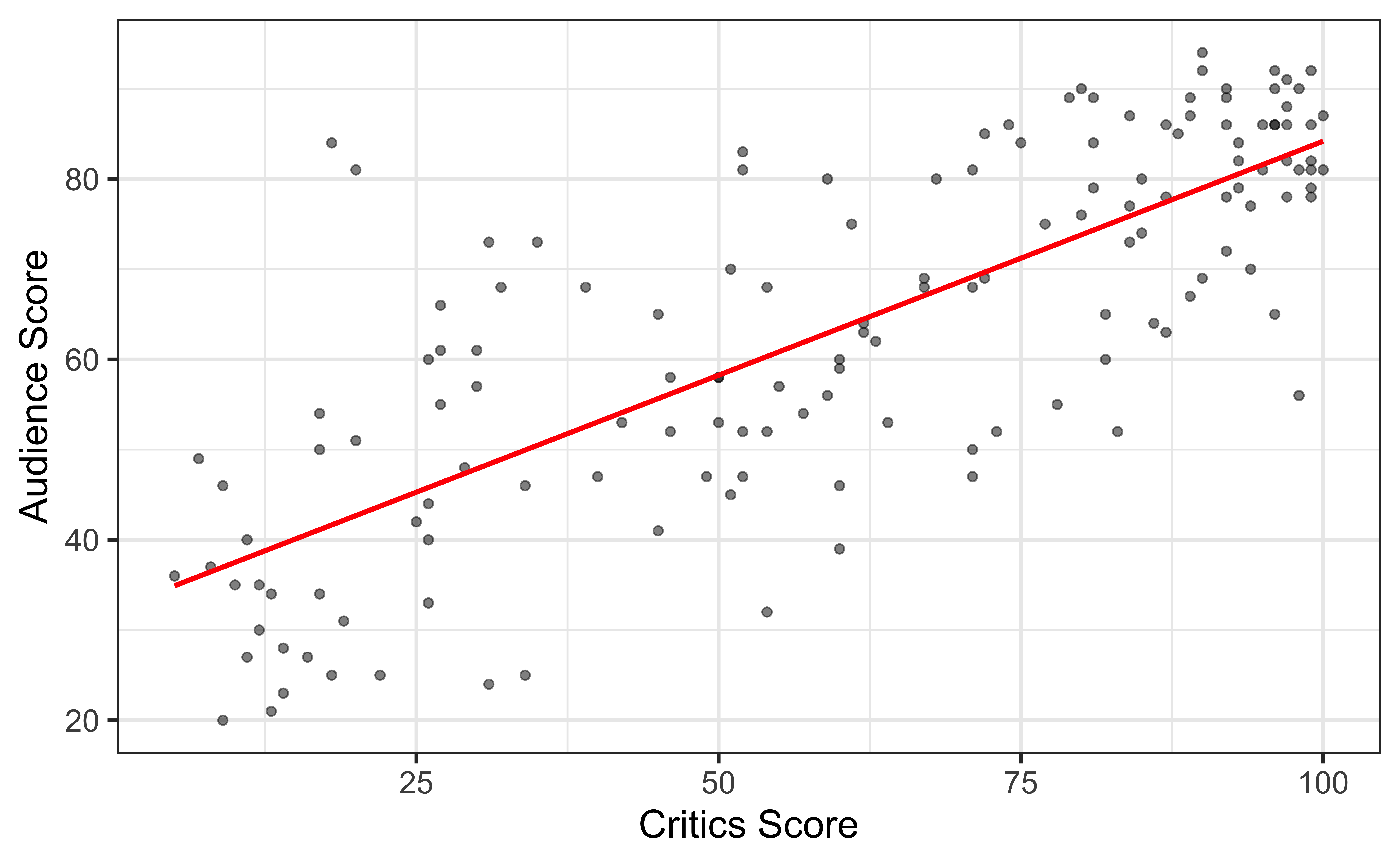
Terminology
Response, Y: variable describing the outcome of interest
Predictor, X: variable we use to help understand the variability in the response
`geom_smooth()` using formula = 'y ~ x'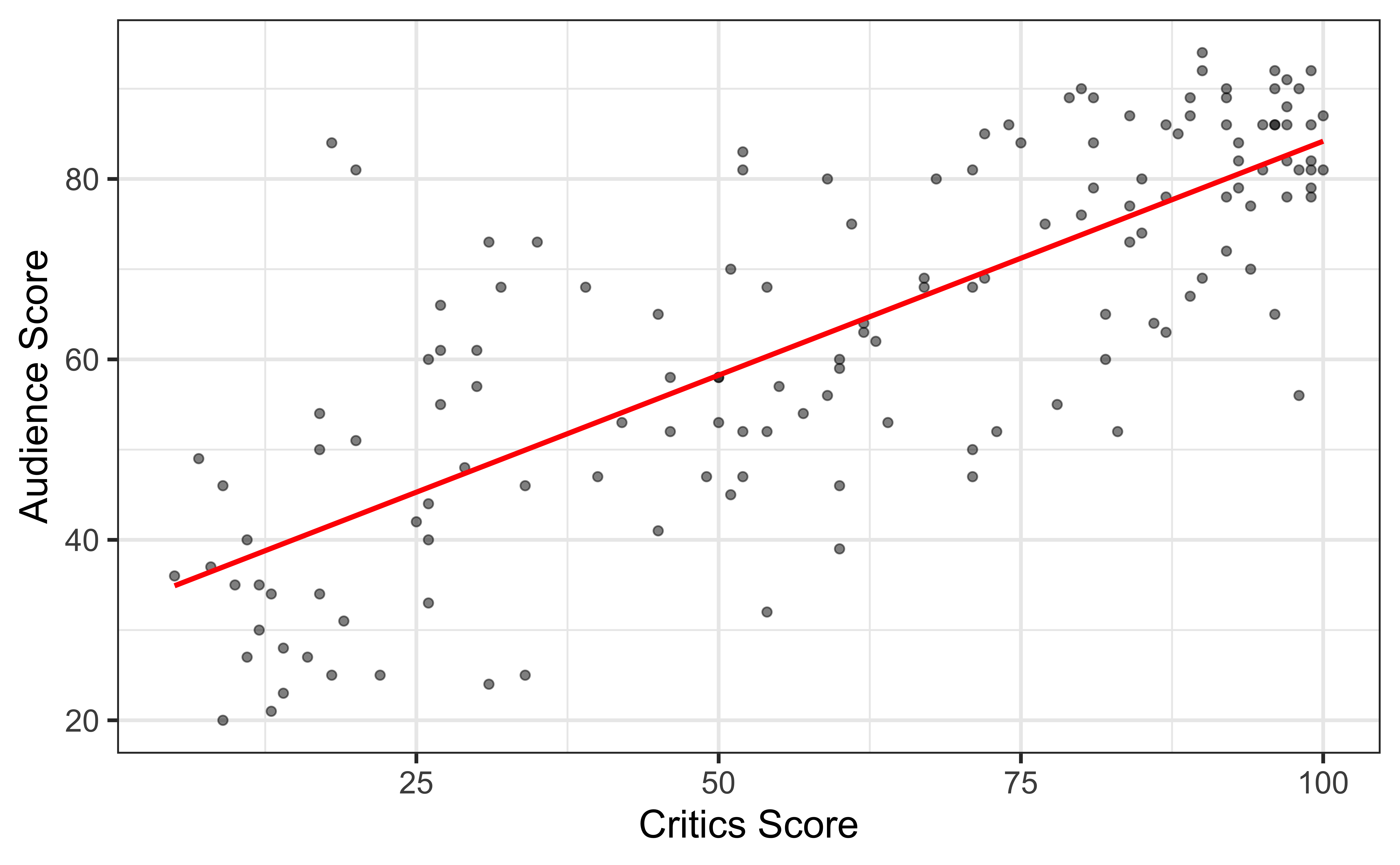
Regression model
\[\begin{aligned} Y &= \color{purple}{\textbf{Model}} + \text{Error} \\[8pt]
&= \color{purple}{\mathbf{f(X)}} + \epsilon \\[8pt]
&= \color{purple}{\boldsymbol{\mu_{Y|X}}} + \epsilon \end{aligned}\]
`geom_smooth()` using formula = 'y ~ x'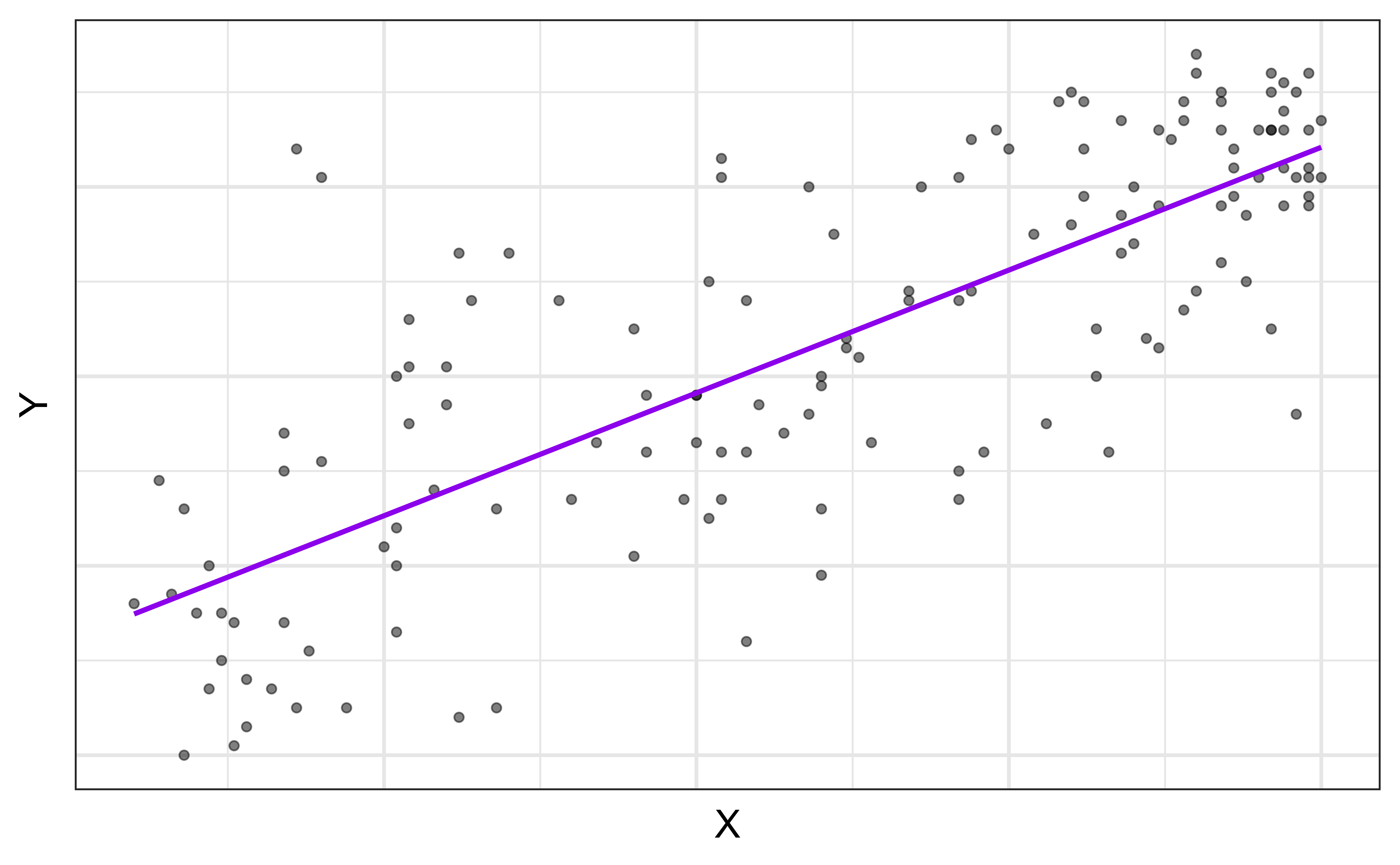
\(\mu_{Y|X}\) is the mean value of \(Y\) given a particular value of \(X\).
Regression model
\[ \begin{aligned} Y &= \color{purple}{\textbf{Model}} + \color{blue}{\textbf{Error}} \\[5pt] &= \color{purple}{\mathbf{f(X)}} + \color{blue}{\boldsymbol{\epsilon}} \\[5pt] &= \color{purple}{\boldsymbol{\mu_{Y|X}}} + \color{blue}{\boldsymbol{\epsilon}} \\[5pt] \end{aligned} \]
`geom_smooth()` using formula = 'y ~ x'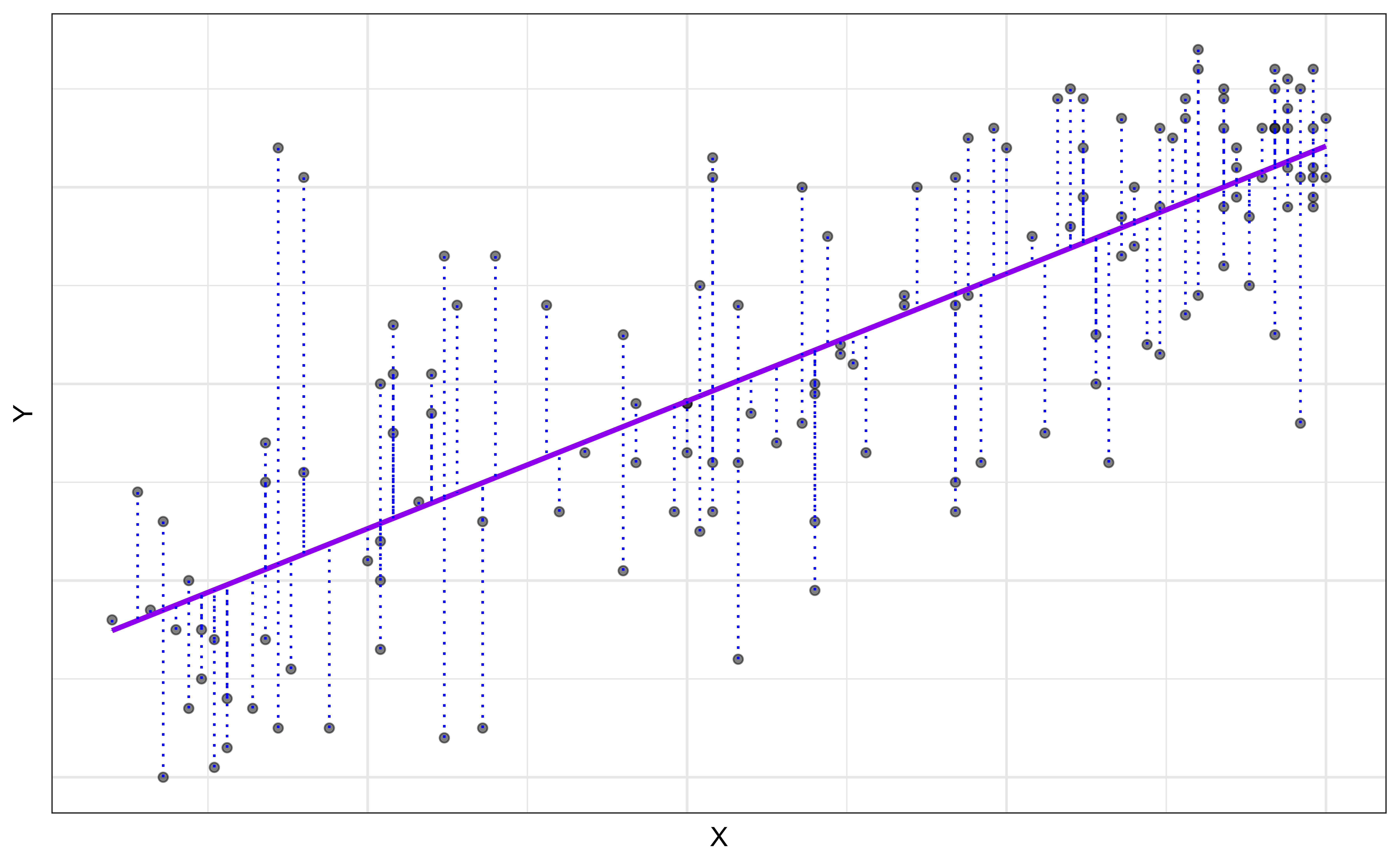
Choosing values for \(\hat{\beta}_1\) and \(\hat{\beta}_0\)
Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.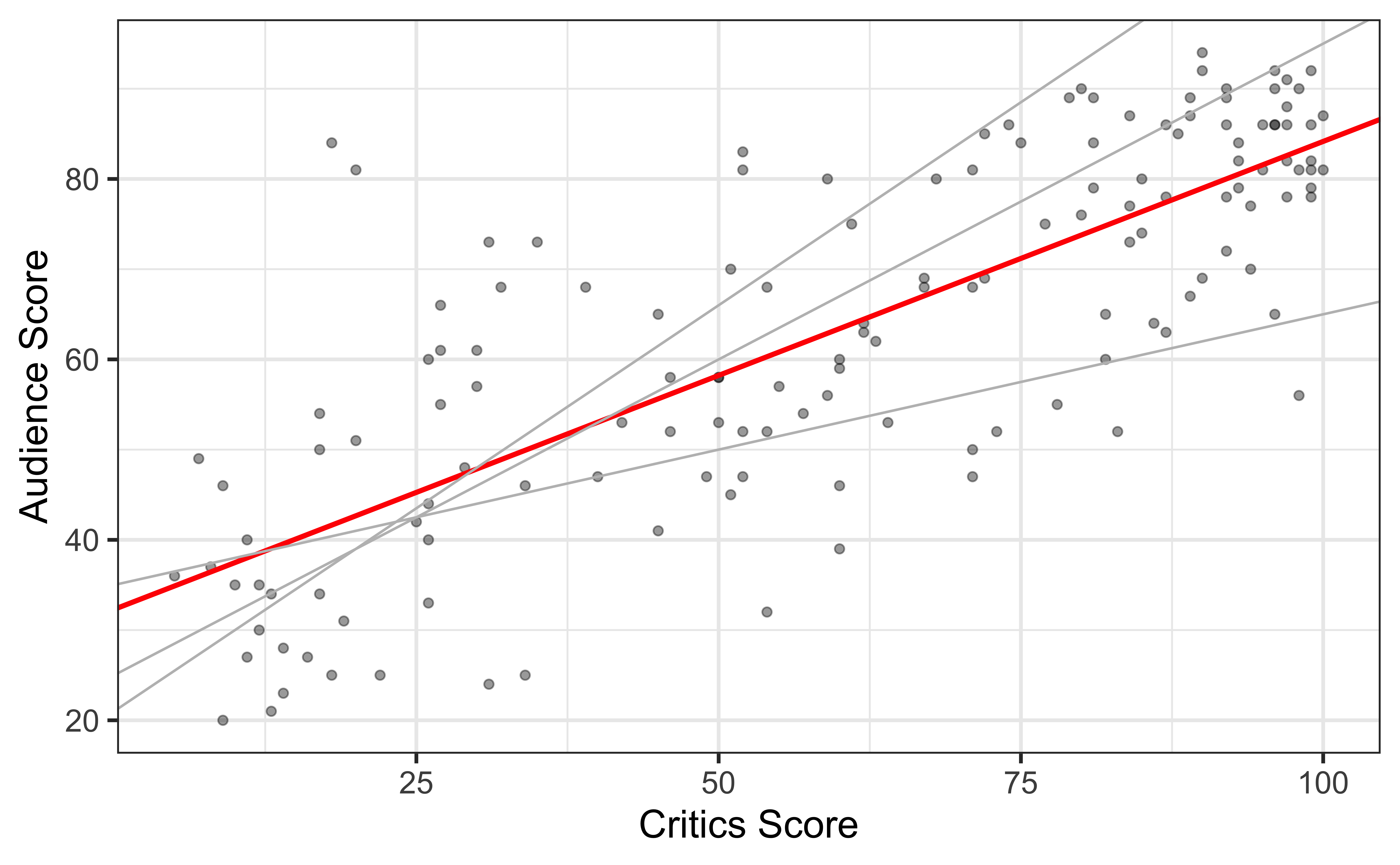
Residuals
`geom_smooth()` using formula = 'y ~ x'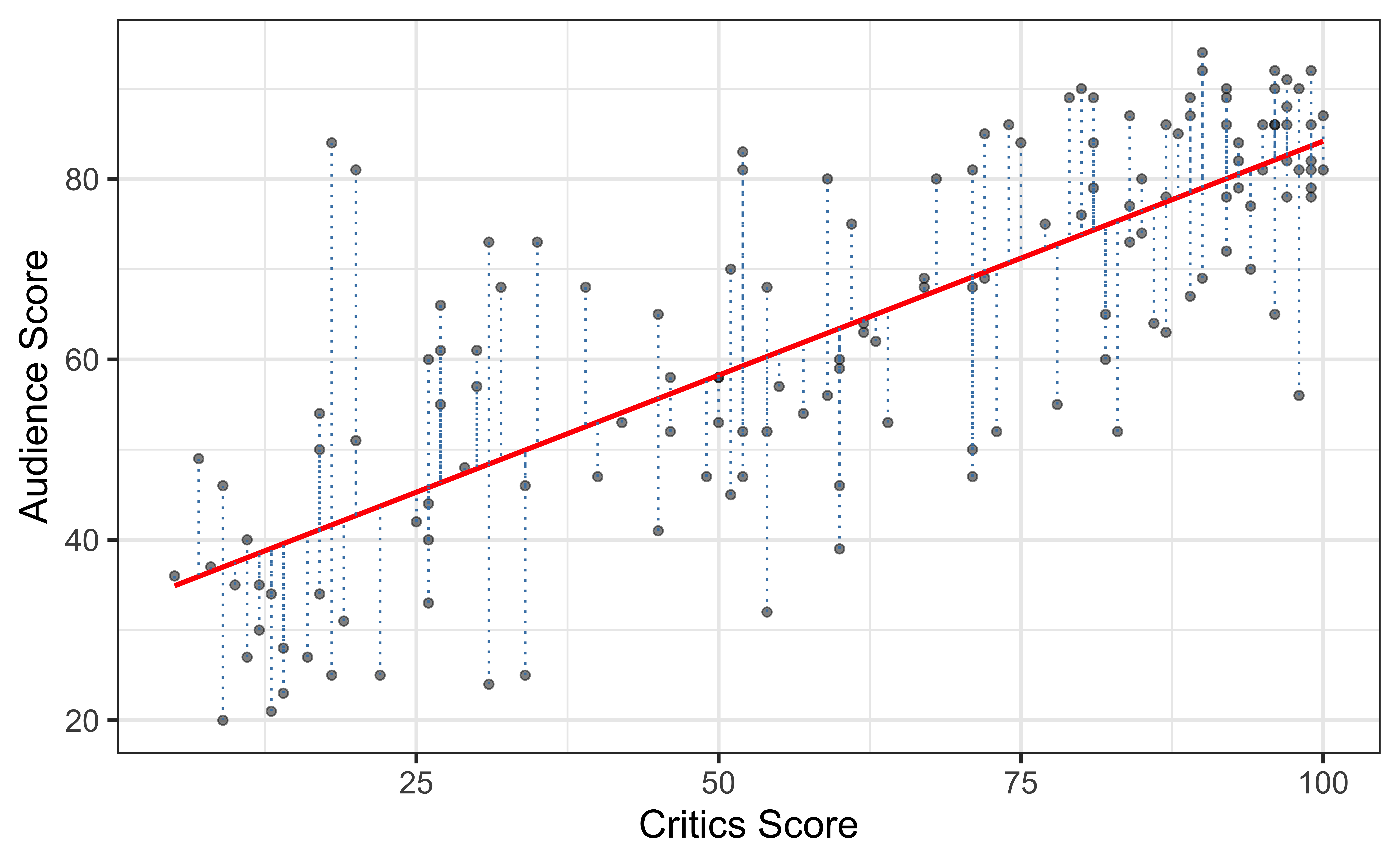
\[\text{residual} = \text{observed} - \text{predicted} = y_i - \hat{y}_i\]
Recap
Used simple linear regression to describe the relationship between a quantitative predictor and quantitative response variable.
Used the least squares method to estimate the slope and intercept.
Interpreted the slope and intercept.
- Slope: For every one unit increase in \(x\), we expect y to change by \(\hat{\beta}_1\) units, on average.
- Intercept: If \(x\) is 0, then we expect \(y\) to be \(\hat{\beta}_0\) units
Predicted the response given a value of the predictor variable.
Used tidymodels to fit and summarize regression models in R.
![]()