The big picture
Analyzing multivariable relationships + Reproducibility
Aug 30, 2023
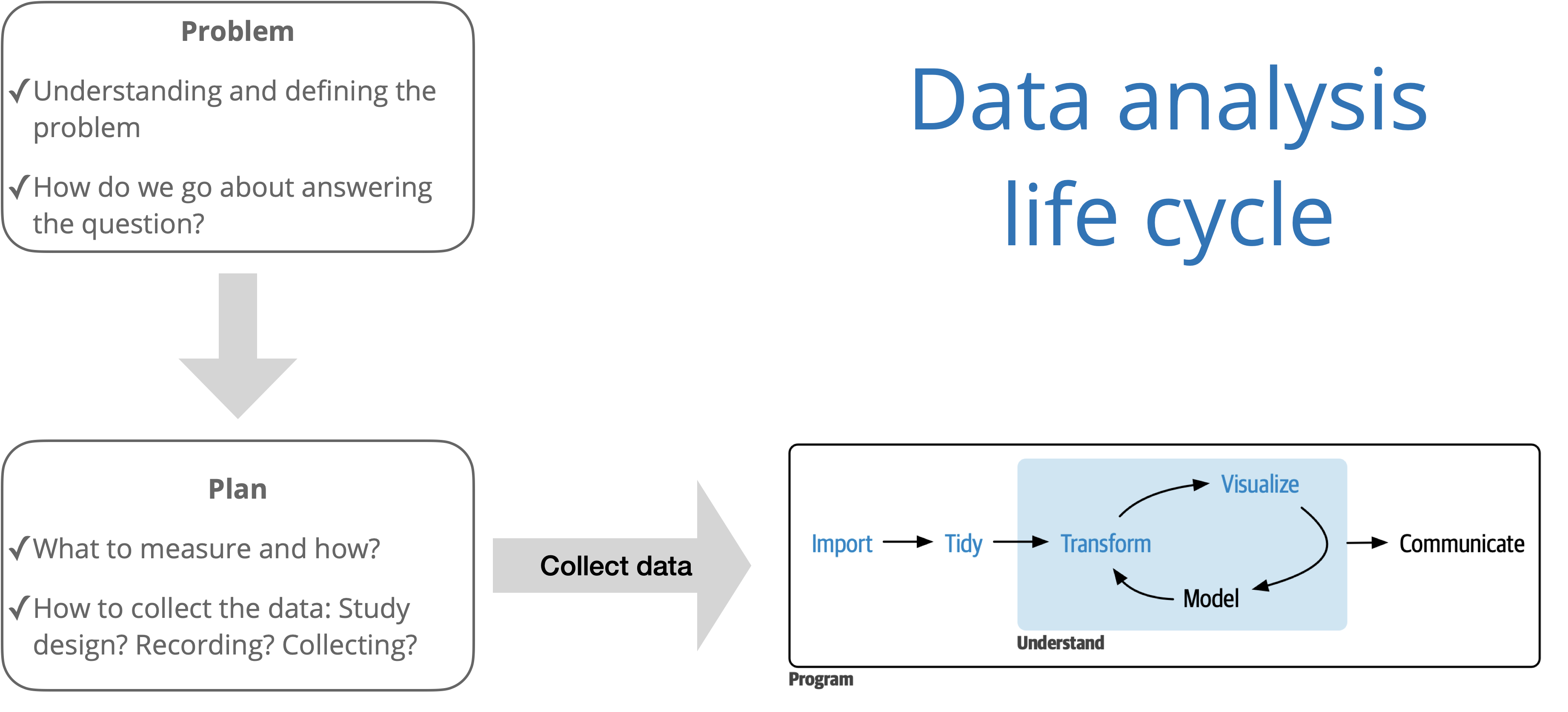
Source: R for Data Science with additions from The Art of Statistics: How to Learn from Data.
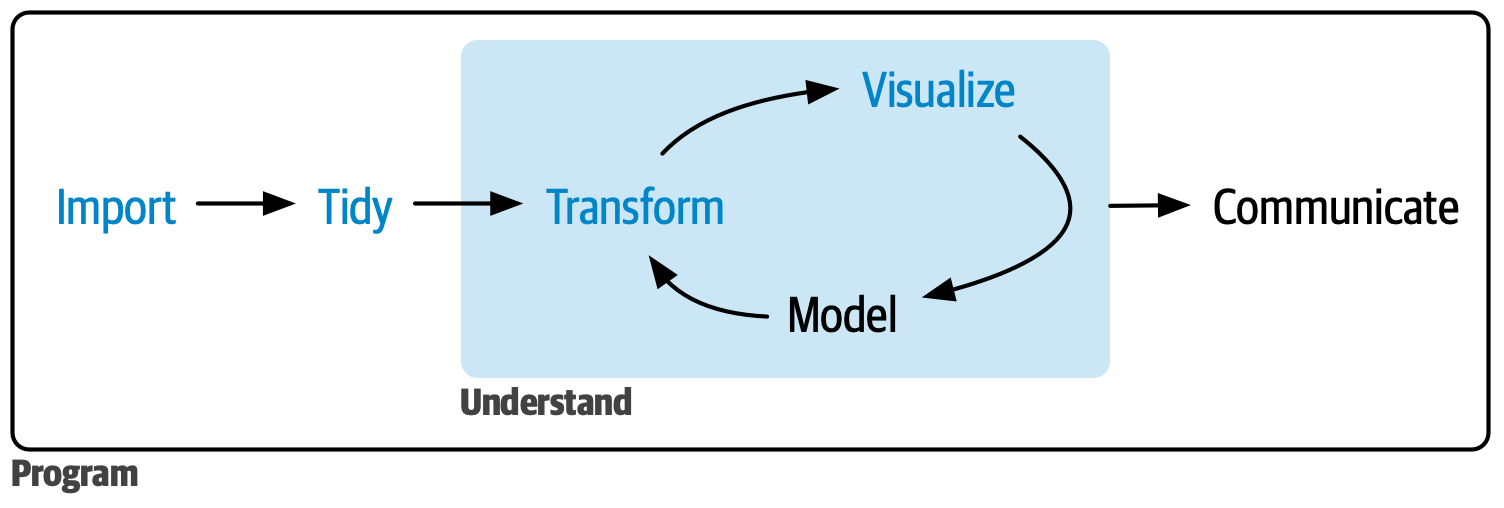
Source:R for Data Science
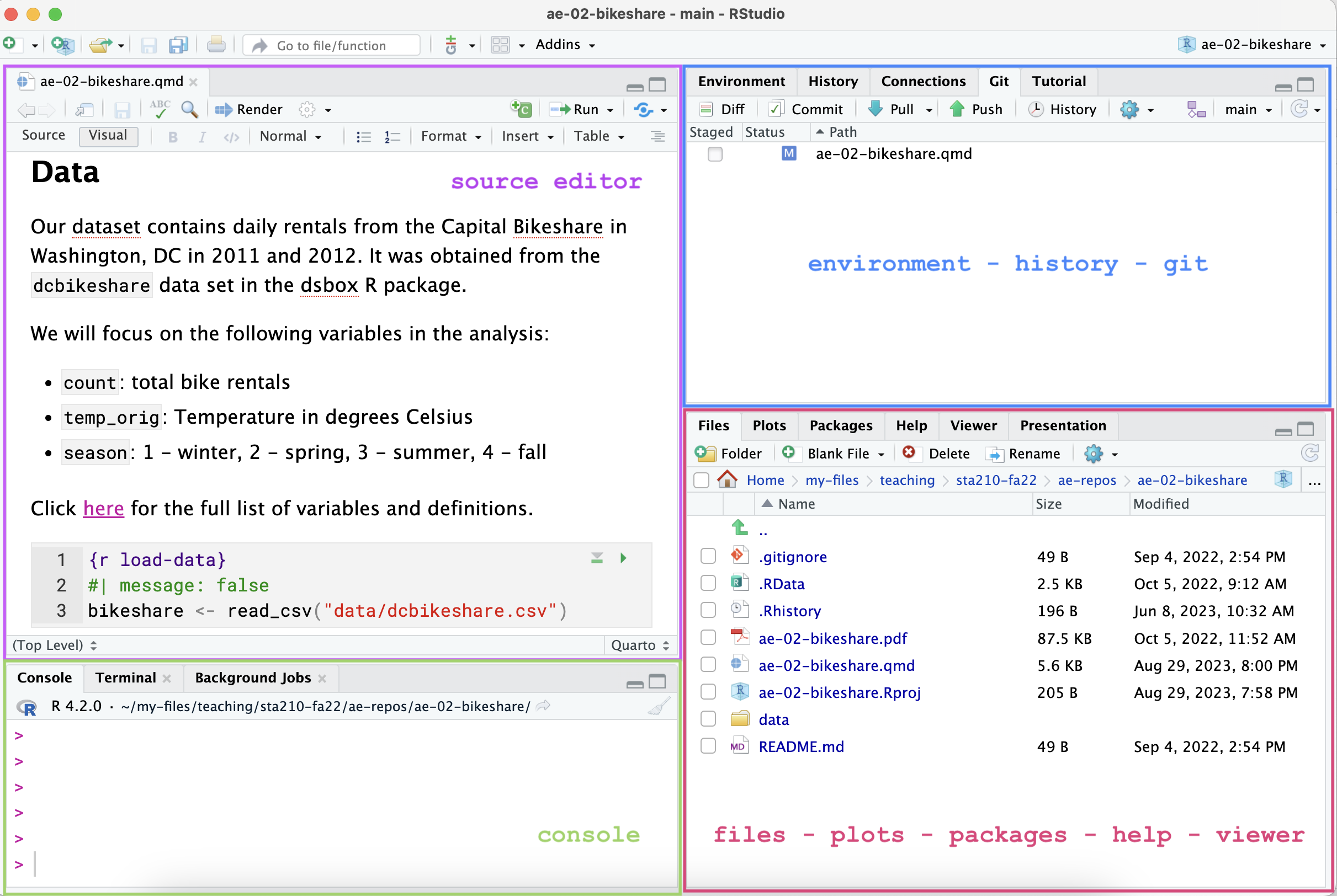
R and RStudio
R is a statistical programming language
RStudio is a convenient interface for R (an integrated development environment, IDE)

RStudio IDE
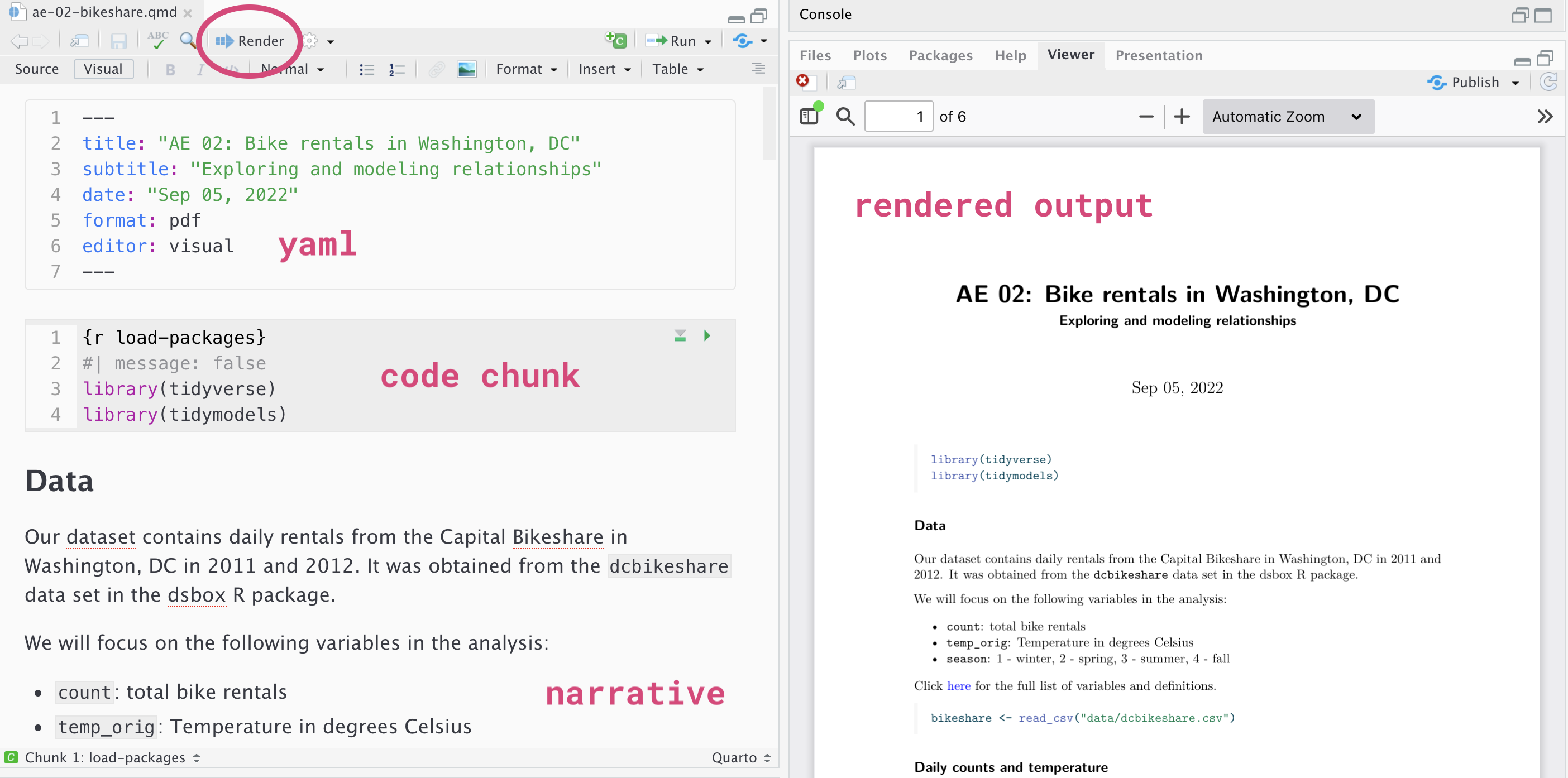
Quarto
What is versioning?
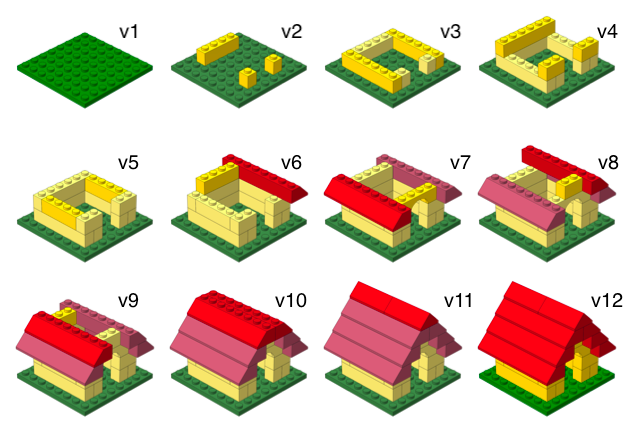
What is versioning?
with human readable messages
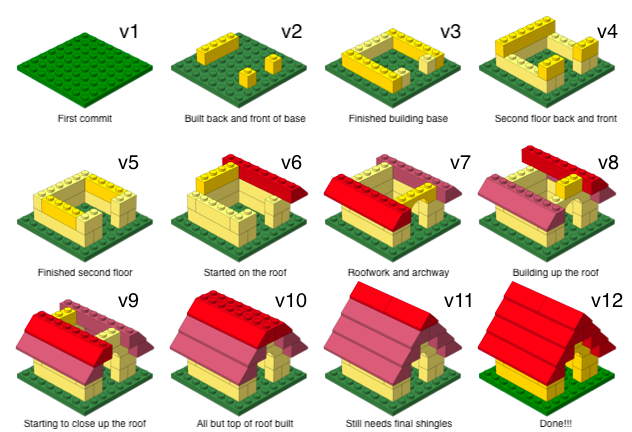
Why do we need version control?

Provides a clear record of how the analysis methods evolved. This makes analysis auditable and thus more trustworthy and reliable. (Ostblom and Timbers 2022)
git and GitHub

- git is a version control system – like “Track Changes” features from Microsoft Word.
- GitHub is the home for your git-based projects on the internet (like DropBox but much better).
- There are a lot of git commands and very few people know them all. 99% of the time you will use git to add, commit, push, and pull.
Univariate exploratory data analysis
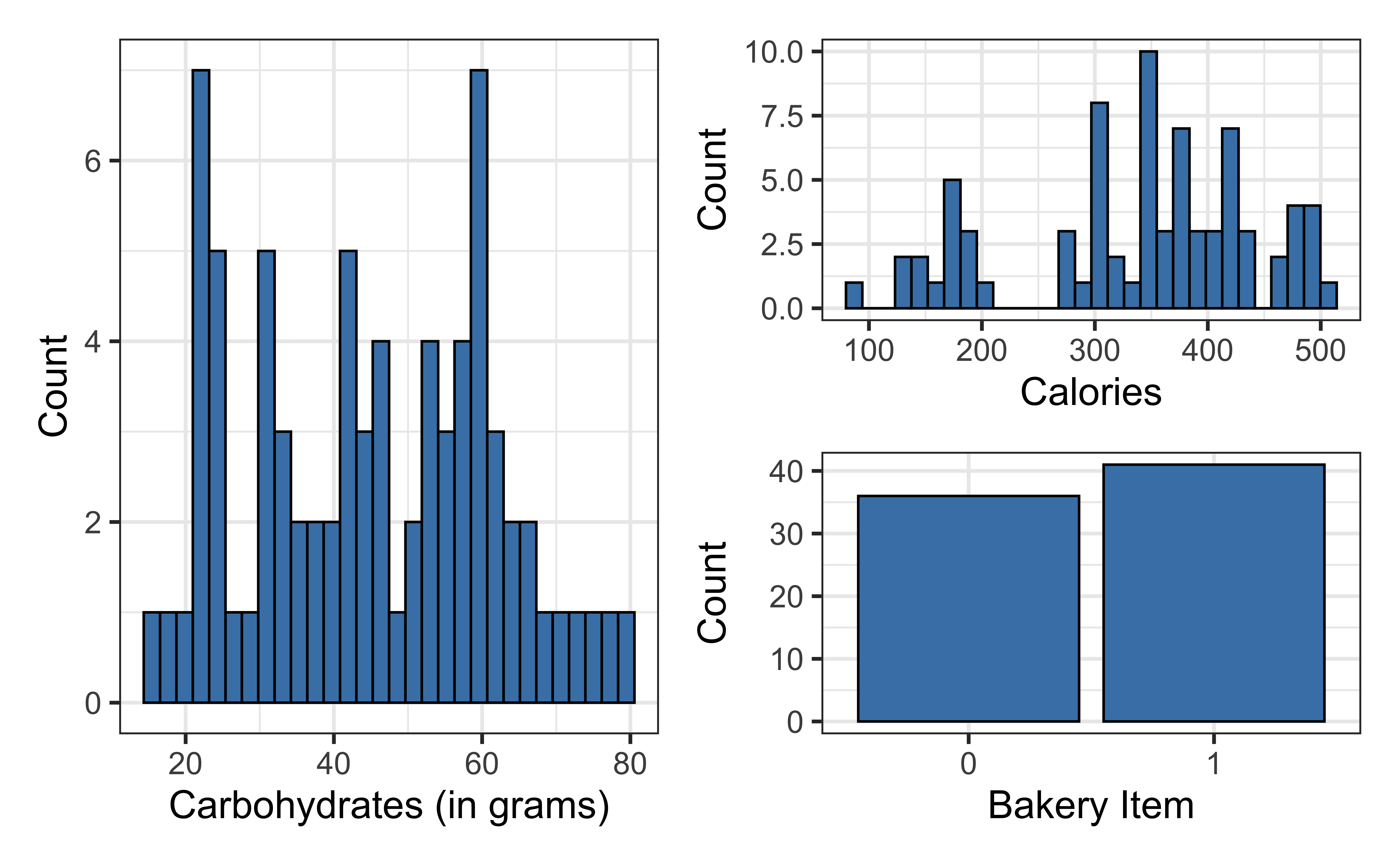
Bivariate exploratory data analysis
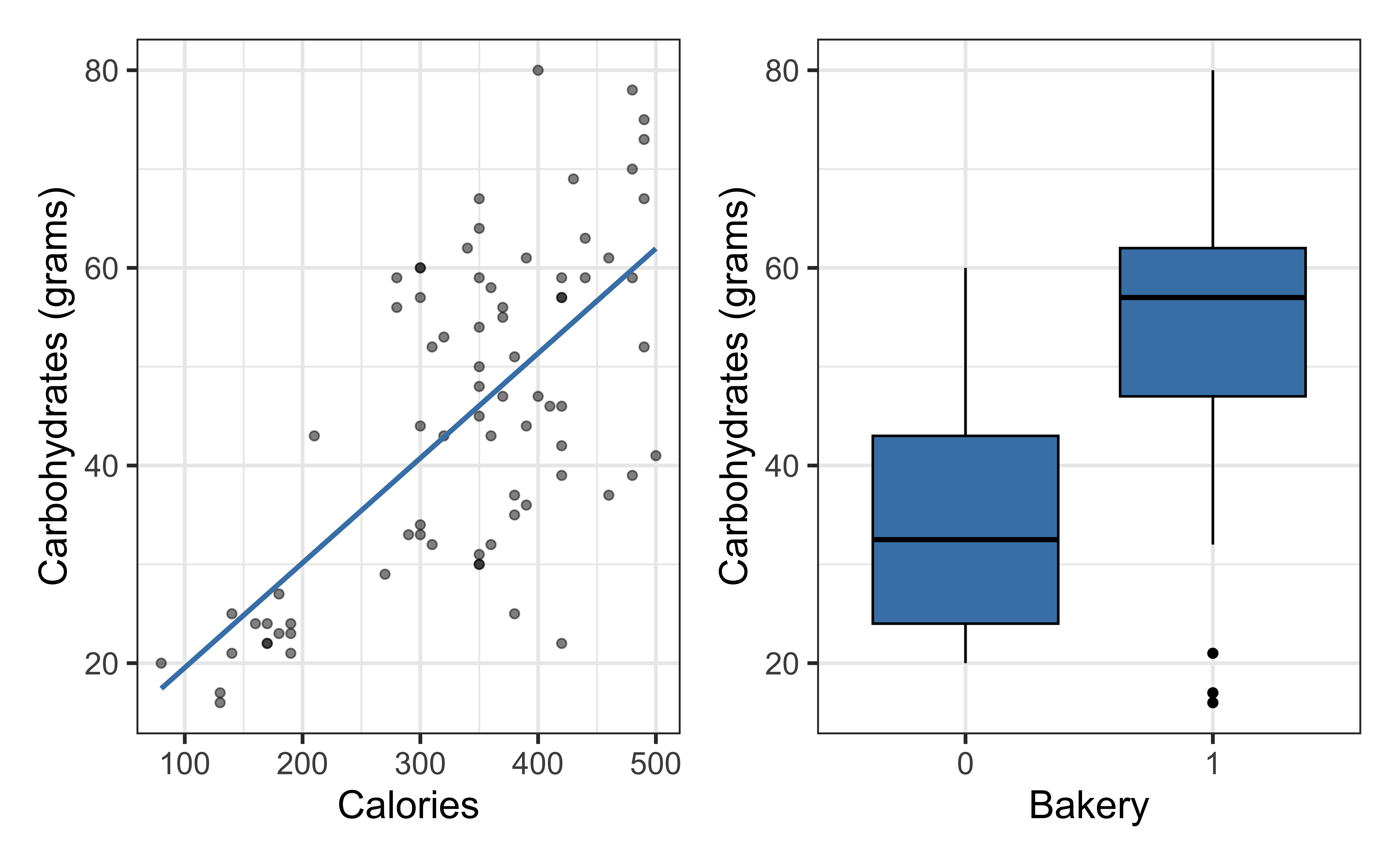
Carb vs. Calories
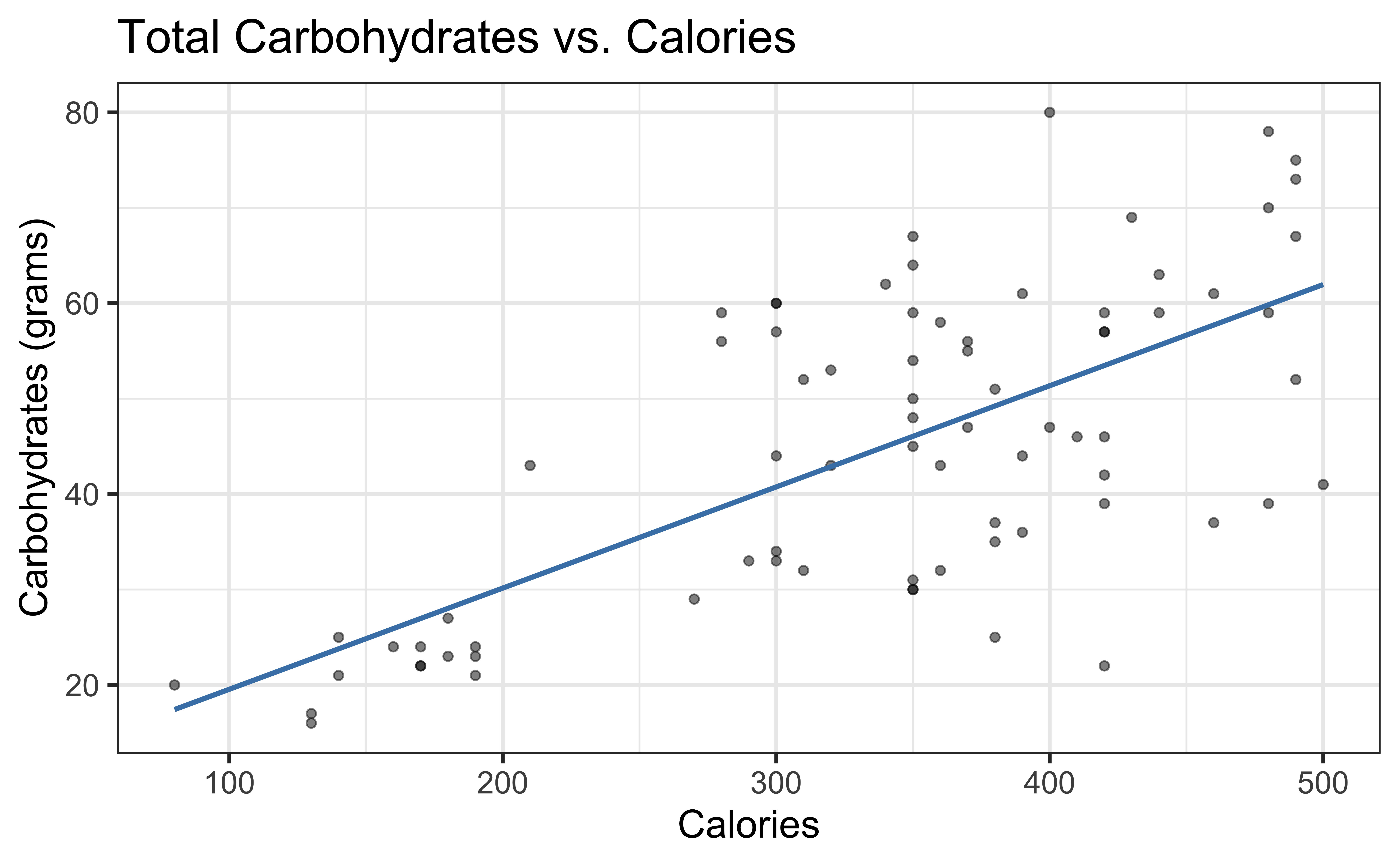
\[\text{carb} = \beta_0 + \beta_1 ~\text{calories} + \epsilon\]
Carb vs. Calories + Bakery
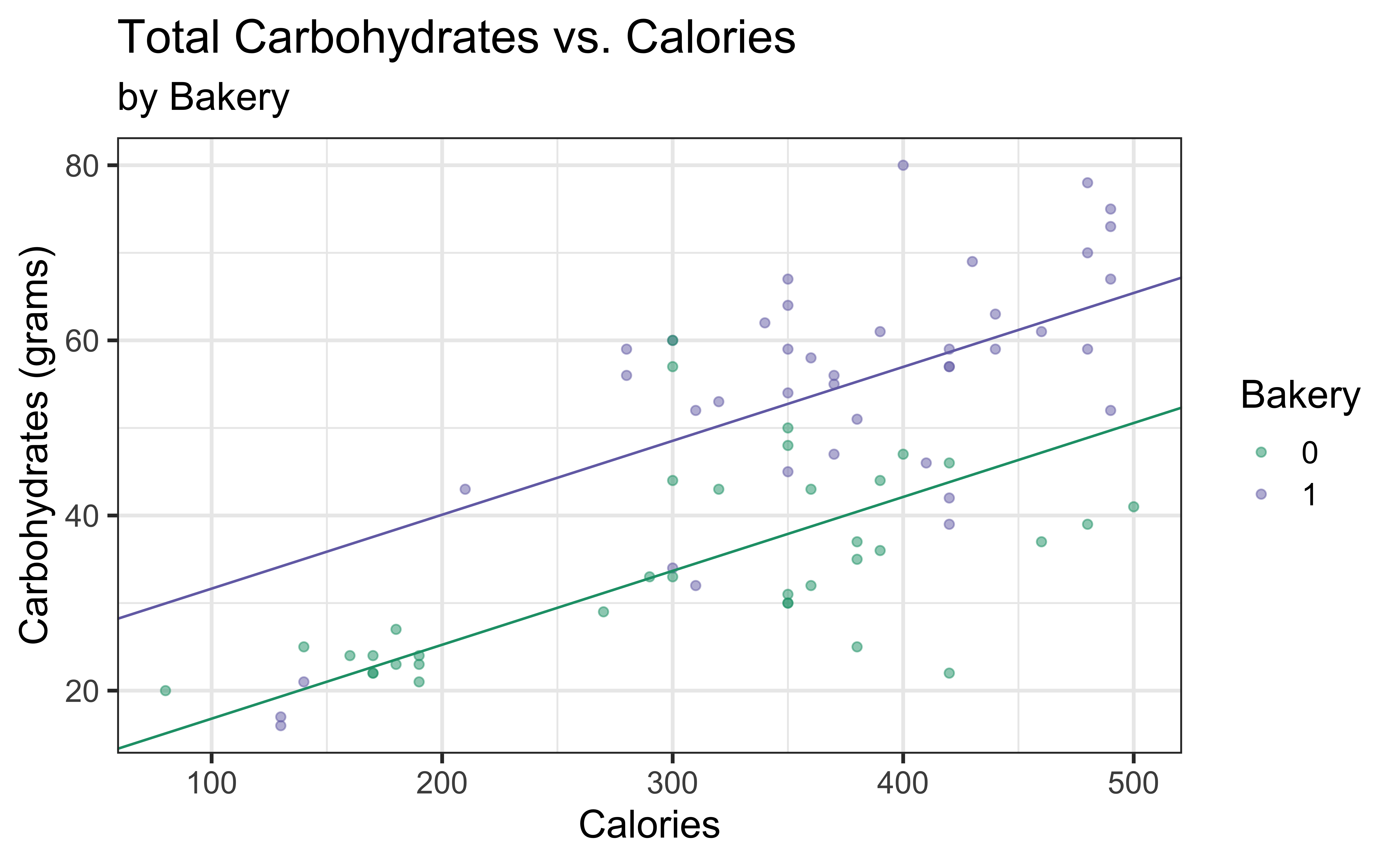
\[\text{carb} = \beta_0 + \beta_1 ~\text{calories} + \beta_2 ~\text{bakery} + \epsilon\]
Carb vs. Calories + Bakery (with interaction)
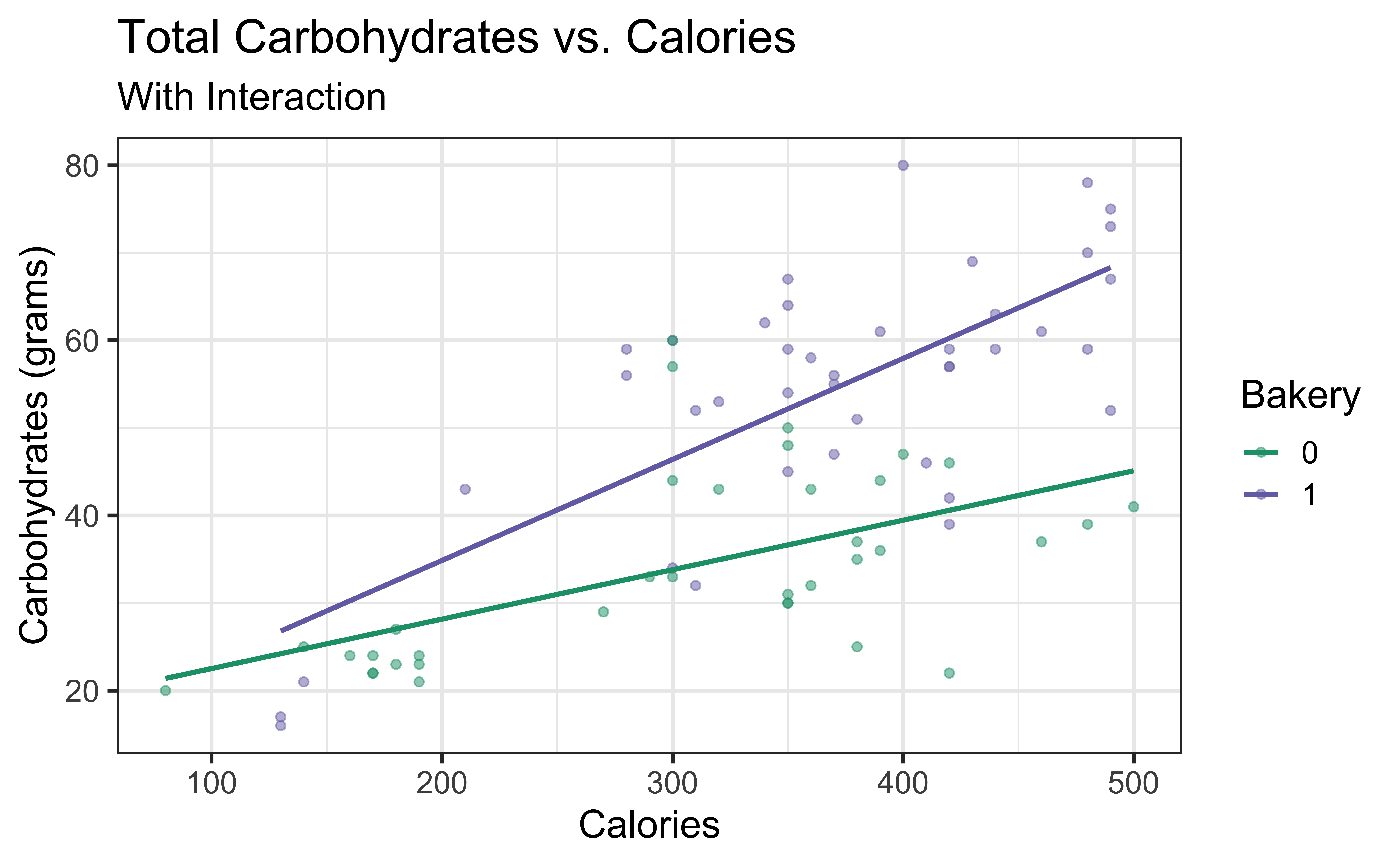
\[{\small \text{carb} = \beta_0 + \beta_1 ~\text{calories} + \beta_2 ~\text{bakery} + \beta_3 ~ \text{calories} \times \text{bakery} + \epsilon}\]
References
![]()