# load packages
library(tidyverse) # for data wrangling and visualization
library(tidymodels) # for modeling
library(openintro) # for the duke_forest dataset
library(scales) # for pretty axis labels
library(knitr) # for pretty tables
library(kableExtra) # also for pretty tables
library(patchwork) # arrange plots
# set default theme and larger font size for ggplot2
ggplot2::theme_set(ggplot2::theme_bw(base_size = 20))SLR: Mathematical models for inference
Sep 18, 2023
Statistician of the day: Regina Nuzzo

Dr. Nuzzo received her PhD in Statistics from Stanford University and is now Professor of Science, Technology, & Mathematics at Gallaudet University. Dr. Nuzzo teaches statistics using American Sign Language.
Her work has appeared in Nature, Los Angeles Times, New York Times, Reader’s Digest, New Scientist, and Scientific American. Primarily, she works to help lay-audiences understand science and statistics in particular. She earned the American Statistical Association’s 2014 Excellence in Statistical Reporting Award for her article on p-values in Nature. Her work led to the ASA’s statement on p-values.
Mathematical representation, visualized
\[ Y|X \sim N(\beta_0 + \beta_1 X, \sigma_\epsilon^2) \]
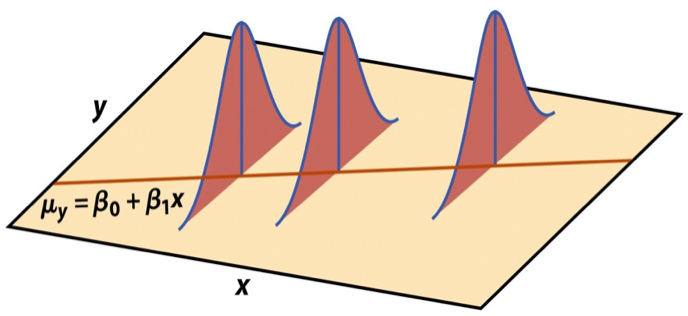
- Mean: \(\beta_0 + \beta_1 X\), the predicted value based on the regression model
- Variance: \(\sigma_\epsilon^2\), constant across the range of \(X\)
- How do we estimate \(\sigma_\epsilon^2\)?
Hypothesis test: p-value
| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 116652.33 | 53302.46 | 2.19 | 0.03 |
| area | 159.48 | 18.17 | 8.78 | 0.00 |
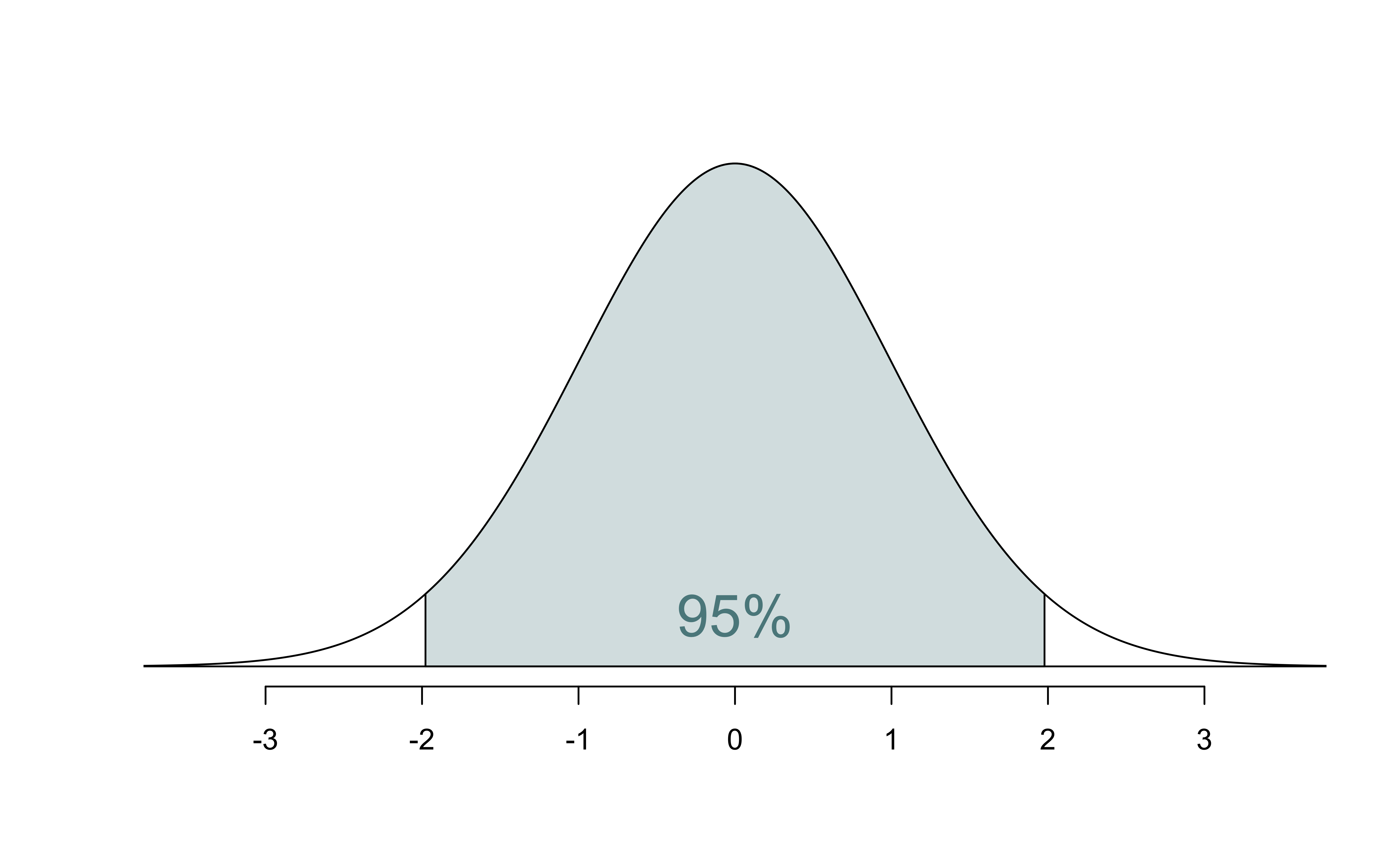
Confidence interval: Critical value
Intervals for predictions
- Suppose we want to answer the question “What is the predicted sale price of a Duke Forest house that is 2,800 square feet?”
- We said reporting a single estimate for the slope is not wise, and we should report a plausible range instead
- Similarly, reporting a single prediction for a new value is not wise, and we should report a plausible range instead
Comparing intervals
Extrapolation
Using the model to predict for values outside the range of the original data is extrapolation.
Calculate the prediction interval for the sale price of a “tiny house” in Duke Forest that is 225 square feet.

No, thanks!
Extrapolation
Why do we want to avoid extrapolation?
![]()